When creating a transport map using the
Select operation, you can apply a distinct
operator. The distinct operator provides the means to
reduce the result set to unique rows in a database
table.
For example, suppose you have a table with
C1 and C2 columns that
represent readings taken from various machines identified
by the combination of a machine ID for column
C1, and station ID for column
C2. A reading is taken from the machine
and written to the database in column C3,
along with a timestamp, written to column
C4. This is a routine process for various
machines throughout the plant. Also, assume that a row is
inserted into the database every 50 milliseconds causing
numerous rows in the database table with the combination of
a machine ID and station ID, each with unique timestamp
values. A Select operation in which you are selecting
columns C1 and C2 that
does not use the distinct operator might fill output
variables log1 and log2
with the column values that represent the same combination
of a machine ID and station ID. The distinct operator is
used to ensure you get only one log1 and
log2 entry per combination of machine ID
and station ID.
The following shows an example transport map with a
Select operation and the Distinct
rows only check box turned on.
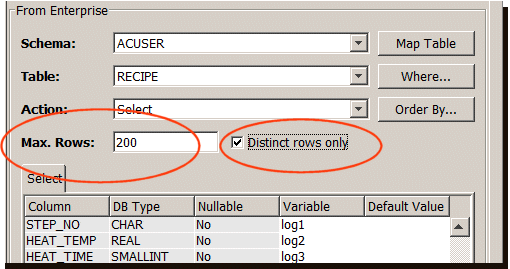
Based on the example transport map, you can select all
C1 and C2 columns, up to
a maximum of 200, in which the machine reading in column
C3 is < 100 (as specified in the Where
clause). The distinct operator ensures that you receive a
result set that has only one entry per combination of
machine ID and station ID. The result set can return up to
200 unique combinations of these two fields. Without the
distinct operator, the results could contain only a few
unique combinations of machine ID and station ID,
intermixed with many duplicate entries.