The thing.aggregate command is used to create bucket aggregations. Unlike metrics aggregations that calculates values (for example, sum, average) over a set of documents; bucket aggregations group documents into buckets. The bucket aggregation also returns the number of documents (for example, Things) that belong to each bucket.
A bucket (in the term bucket aggregations) means a range of potential values that are grouped together. For example in looking at the number of miles a vehicle has traveled, it is possible to arbitrarily construct the following ranges (the ‘bucket’ name in parentheses): 0-999 miles (new car), 1,000-5,000 miles (mildly used car), 5,001-99,999 miles (moderately used), 100,000+ miles (used car). Similarly, temperature ranges read by sensors can be described in buckets could be used: 23°C and under (cold), 24°C to 29°C (warm), 30°C and more (hot). Our use of bucket aggregation is counting the number of Things that have a value that fits into one of the buckets: 10 new cars, 5 mildly used car, 7 moderately used car, and 1 used car; 51 sensors are cold, 72 are warm, and 66 are hot.
The thing.aggregate is designed to provide counts of the number of Things in various states, whether it be based on the current attribute value (string), current property value (integer or float), or a value from the LWM2M data structure (which could be analogous to either an attribute or a property).
Common Request Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| query | String | Yes | Query to filter list of Things to be aggregated |
| objId+instId+resId | Integer | All 3 must be specified to aggregate a LWM2M resource value, this is expanded into field lwm2m.objects.<objId>.instances.<instId>.resources.<resId>.lastKnownValue for the aggregation. |
|
| property | Integer | Specifies a property key to aggregate, this field is expanded into properties.<property>.value |
|
| attribute | Boolean | Specifies an attribute key to aggregate, this field is expanded into attrs.<attribute>.value |
|
| field | String | If you do not use any of the above 3 methods to define the field, you can specify a field. For example: lastSeen |
TR50 Request
{
"1": {
"command": "thing.aggregate",
"params": {
"field":"lastSeen",
"aggregation":"date_range",
"ranges":["3M","1M","7D","1D","0D"]
}
}
}
Request Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| Aggregation | String | Yes | date_range - A range aggregation that is dedicated for date values |
| ranges | Array | An array of strings from oldest to newest with time intervals for the buckets to aggregate. In this request the field lastSeen is used for the aggregation. "M" indicates months, and "D" indicates days |
TR50 Response
If the command is sent successfully a success message is returned. Otherwise, an error and error message will be returned.
{
"1",
"data": {
"success": true,
"params": {
"count": 6,
"result": [
{
"to": "2018-11-14T00:00:00Z",
"count": 16
},
{
"from": "2018-11-14T00:00:00Z",
"to": "2019-01-14T00:00:00Z",
"count": 0
},
{
"from": "2019-01-14T00:00:00Z",
"to": "2019-02-07T00:00:00Z",
"count": 0
},
{
"from": "2019-02-07T00:00:00Z",
"to": "2019-02-13T00:00:00Z",
"count": 0
},
{
"from": "2019-02-13T00:00:00Z",
"to": "2019-02-14T00:00:00Z",
"count": 0
},
{
"from": "2019-02-14T00:00:00Z",
"count": 3
}
]
}
}
}
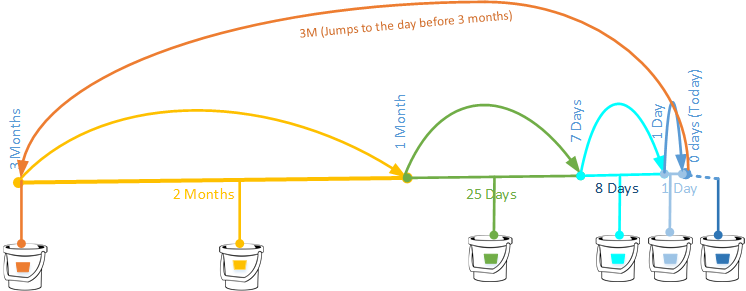
Response Parameters
| Name | Type | Description |
|---|---|---|
| count | Integer | The total number of buckets. |
| result | Array |
The result set of the returned buckets. In the above example 6 buckets are returned. Refer the diagram above to understand the buckets returned. |
| count(within results) | Integer | The counts within each buckets. |
{
"1": {
"command": "thing.aggregate",
"params": {
"objId":"4",
"instId":"0",
"resId":"2",
"field": "properties.rssi.value",
"aggregation":"histogram",
"interval":5
}
}
}
| Name | Type | Required | Description |
|---|---|---|---|
| Aggregation | String | Yes | histogram - The histogram aggregation is applied on numeric values extracted from the documents. The examples for a document includes - properties, attributes, and so on. |
| interval | Integer |
The interval between buckets. The interval is an integer value that defines the range (buckets) into which the values will be grouped together. For example, consider the following thing.property values: (0, 2, 2, 3, 4, 6, 8, 8, 9, 11, 11, 12, 23), and the interval is set to 5, the aggregation function would create 4 buckets: 0 (0-4), 5 (5-9), 10 (10-14), and 20 (20-24), and each bucket would contain the following results:
|
|
| showEmpty | Boolean |
Defaults to false and will suppress returning buckets that have a zero value (meaning, no values exist that fit the criteria for the range defined by the bucket). The showEmpty option overrides that behavior and will cause empty buckets to be returned. In the above example, there is no 15 bucket for the range 15-19 as no values exist in that range. If the showEmpty parameter is set to true, it will return the 15 bucket (in addition to the other expected buckets):
|
{
"1": {
"command": "thing.aggregate",
"params": {
"field":"lastSeen",
"aggregation":"date_histogram",
"intervalSpecial":"month"
}
}
}
| Name | Type | Required | Description |
|---|---|---|---|
| Aggregation | String | Yes | date_histogram - A date_histogram aggregation is similar to the normal histogram, but it is used only for date/time values |
| intervalSpecial | String | A string parameter defining the time based period used to group results. Possible values are: “#ms”, “#s”, “#m”, “#h”, “#d”, “day”, “week”, “month”, “quarter”, and “year”, where the “#” can be replaced with a numeric value (such as “30m” representing 30 minute intervals. | |
| interval | Integer | A numeric parameter representing the number of seconds for each interval. Such that a grouping by day could be represented with interval=86400 (there are 86400 seconds in a day). It is equivalent to intervalSpecial=”86400s”, intervalSpecial=”1d”, or intervalSpecial=”day”. | |
| showEmpty | Boolean | Defaults to false and empty buckets will not be shown. If set to true, buckets with 0 items will be returned. |
{
"1": {
"command": "thing.aggregate",
"params": {
"objId":"4",
"instId":"0",
"resId":"2",
"aggregation":"range",
"ranges":[-115.0,-105.0,-85.0,-60.0]
}
}
}
| Name | Type | Required | Description |
|---|---|---|---|
| Aggregation | String | Yes | range - A range aggregation. |
| ranges | Array | The array values is used to create range of buckets. For example, the following buckets are created for the above example: <-115, -115 ~ -105, -105.0 ~ -85.0, -85.0 ~ -60.0, and >60.0 |
{
"1": {
"command": "thing.aggregate",
"params": {
"aggregation":"terms",
"query": "*",
"field":"attrs.firmware_version.value"
}
}
}
| Name | Type | Required | Description |
|---|---|---|---|
| Aggregation | String | Yes | terms - A multi-bucket value source based aggregation where buckets are dynamically built - one per unique value. |
| terms | Array | The terms aggregation will return the buckets of terms. This aggregation would be generally used for attributes, where you get a count for the number of Things that have similar string defined for specific attribute. For example (Thing definition vehicle, attribute key type): The response is 20 ‘car’, 12 ‘truck’, 8 ‘van’. |
Here in is the above example JSON the attribute with the key firmware_version is requested and the response is shown below.
TR50 Response
{
"1": {
"success": true,
"params": {
"count": 5,
"result": [
{
"key": "x0z1-1134ba1",
"count": 3
},
{
"key": "bcx-1.1.0",
"count": 2
},
{
"key": "xdk-2.0.1",
"count": 2
},
{
"key": "30.00.002",
"count": 1
},
{
"key": "x0z1-1134ca3",
"count": 1
}
]
}
}
}